
近年は「siri」や「OK Google( Google アシスタント)」や「Alexa」などの音声による端末の操作が日常になりつつあります。
これらはざっくりいうと
「音声を読みとる」→「何と言っているか認識する」→「認識した命令を実行」
という仕組みです。
今回は「認識した命令を実行」の部分は無視し、 「音声を読みとる」→「何と言っているか認識する」 、いわゆる音声認識というものを少し紹介しようと思います。
音声認識とは何か?
これまたざっくりいうと
「発せられた言葉をコンピュータに認識させて文字列などに変換する」
というものです。専門分野でないので細かい部分は許してください。
音声認識APIを提供している企業
APIとは、アプリケーション開発を便利にするツール的なものとでも思ってください。
そして、意外と知られていませんが、世界的な超大手IT企業が音声認識用のAPIを提供しているので、その一部を紹介します。
Microsoft
Windowsやofficeなどで言わずとしれたMicrosoft社。
以下は公式ページに載っているサンプルコードです。
import azure.cognitiveservices.speech as speechsdk
def from_mic():
speech_config = speechsdk.SpeechConfig(subscription="<paste-your-speech-key-here>", region="<paste-your-speech-location/region-here>")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
print("Speak into your microphone.")
result = speech_recognizer.recognize_once_async().get()
print(result.text)
from_mic()非常に簡単ですね。ただし、本記事作成時点では
- Microsoftアカウントとは別途の登録が必要
- 登録にはクレジットカード登録が必須
- 登録から12ヶ月は無料で使用可能
- 登録から30日間のみ使用可能な$200のクレジット付き
という条件&特典があります。ご利用は計画的に。
みんな大好きGoogle先生。
こちらは無料版と有料版があります。
無料版は「Google Speech Recognition」といい
import speech_recognition as sr
def get_speaking_value():
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source)
print("Speak into your microphone.")
audio = r.listen(source)
text = r.recognize_google(audio, language="ja-JP")
print(text)
get_speaking_value()このようにこちらも非常に簡単にできる上、
精度もかなり高く感じます。
また、有料版は公式ページでは以下のようになっています。
# Imports the Google Cloud client library
from google.cloud import speech
# Instantiates a client
client = speech.SpeechClient()
# The name of the audio file to transcribe
gcs_uri = "gs://cloud-samples-data/speech/brooklyn_bridge.raw"
audio = speech.RecognitionAudio(uri=gcs_uri)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="en-US",
)
# Detects speech in the audio file
response = client.recognize(config=config, audio=audio)
for result in response.results:
print("Transcript: {}".format(result.alternatives[0].transcript))ただしこちらも、本記事作成時点で
- Googleアカウントとは別途の登録が必要
- 登録にはクレジットカード登録が必須
- 登録から12ヶ月のみ使用可能な$300のクレジット付き
という条件&特典があります。
Amazon
通販でおなじみのAmazon社。
エンジニア界隈では当たり前になっていますが、実はクラウドコンピューティング業界最大手。
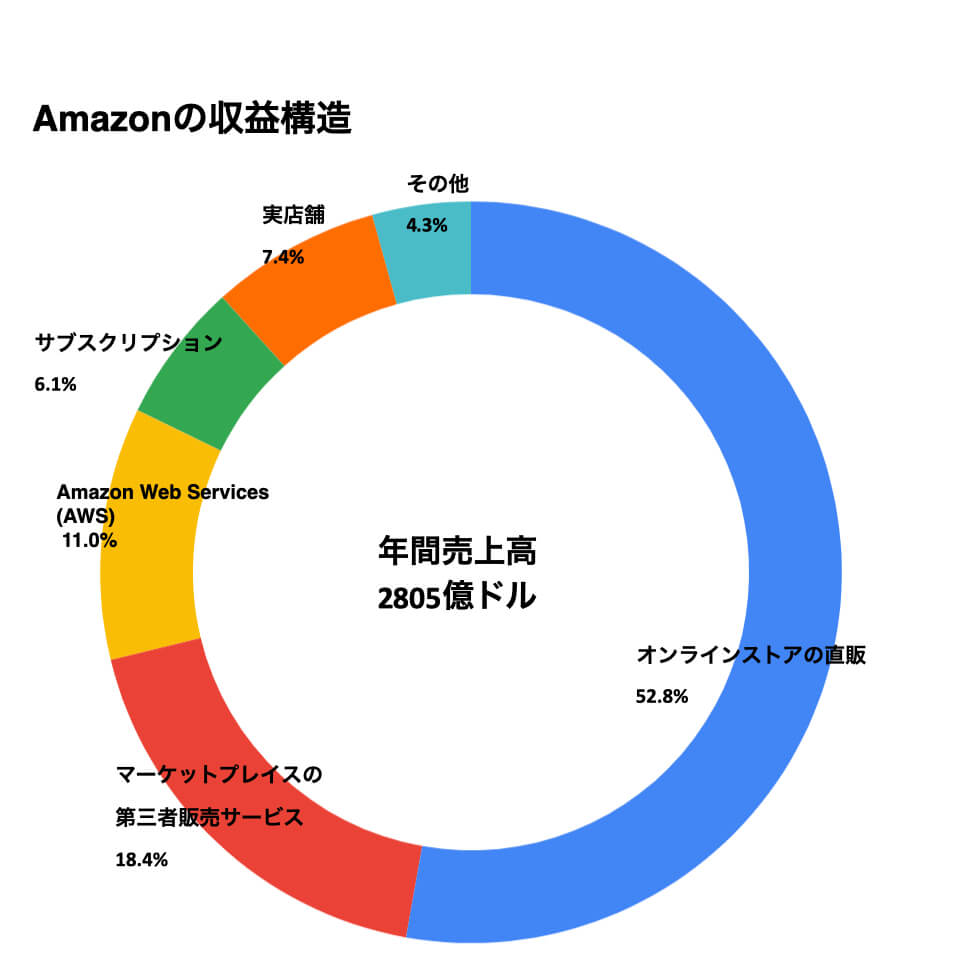
このように通販だけの企業ではありません。
また、Amazonの音声認識はリアルタイムではなく1、「 Amazon s3」というサービスで用意したオンラインストレージ上に録音した音声ファイルをアップロードし、「Amazon Transcribe」というサービスで音声データを「JSON」というデータ形式に変換するというものです。
そのため、リアルタイム音声認識が直接文字列を出力するのに対し、音声データの中で「いつ」「どのような」発言があったかなどのデータが取れ、YouTubeなどの動画共有サイト用の動画に字幕をつけることもできます。
以下は公式ページのサンプルコード
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe')
job_name = "job-name"
job_uri = "s3://DOC-EXAMPLE-BUCKET1/key-prefix/file.file-extension"
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='wav',
LanguageCode='en-US'
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)そして以下は実行時の出力例
{
"jobName":"job ID",
"accountId":"account ID",
"results": {
"transcripts":[
{
"transcript":" that's no answer"
}
],
"items":[
{
"start_time":"0.180",
"end_time":"0.470",
"alternatives":[
{
"confidence":0.84,
"word":"that's"
}
]
},
{
"start_time":"0.470",
"end_time":"0.710",
"alternatives":[
{
"confidence":0.99,
"word":"no"
}
]
},
{
"start_time":"0.710",
"end_time":"1.080",
"alternatives":[
{
"confidence":0.87,
"word":"answer"
}
]
}
]
},
"status":"COMPLETED"
}そしてこちらも漏れなく、
- Amazonアカウントとは別途の登録が必要
- 登録にはクレジットカード登録が必須
- 登録から12ヶ月は無料で使用可能
という条件&特典があります。
音声認識ソフト
ここまでは開発者が如何に音声をいじるかの話でしたが、以下ではユーザーが音声で文字を入力するいくつかのソフトウェアを紹介します。
Windows音声認識
Windows標準アプリです。
Windows上で動くアプリに音声入力が可能ですが、
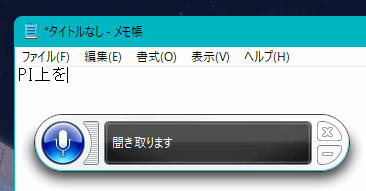
このように精度はかなり悪いです。
Microsoft Office
オフライン版Officeにはないらしいのですが、筆者はOffice 365に登録しているため、Officeの音声認識機能が使用可能です。

Microsoft Office Wordの場合はホームタブの「ディクテーション」ボタンを押すと音声読み取りモードに入り
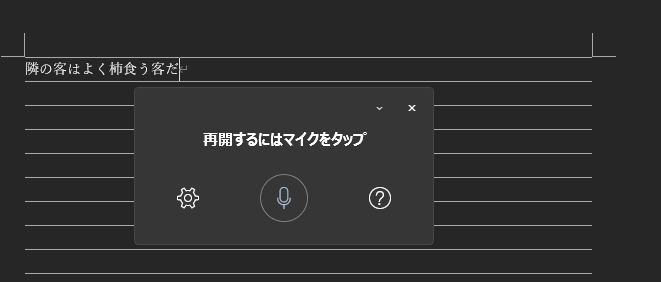
かなりの精度かつ高速に文字起こししてくれます。
これがあれば議事録作りかなり楽になりそうですね。
Googleドキュメント
こちらはGoogleが提供しているWeb版Officeのような、というかそのものです。
いくらでも作り放題なGoogleアカウントと、インターネットに接続されたコンピュータがあれば無料で使い放題な便利なしろものです。
Google ドライブにアクセスし、左上の「+新規」ボタンなり右クリックからなりでGoogle ドキュメントを作成し
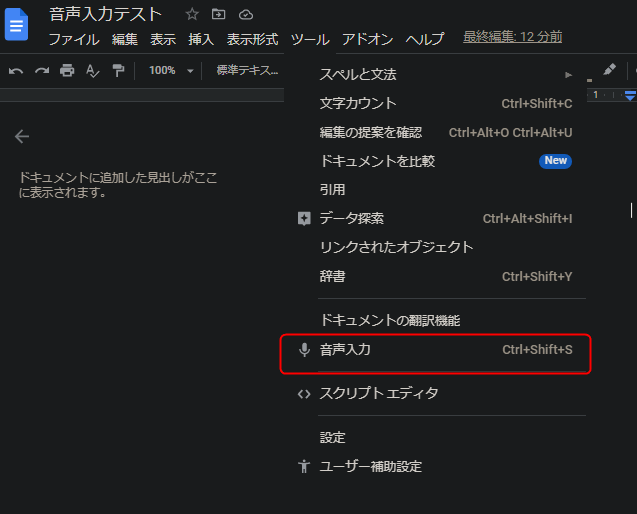
メニューから「音声入力」をクリック。すると
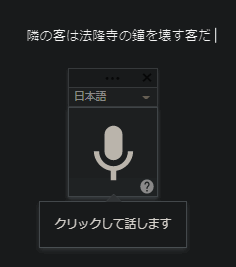
このように精度も高く文字入力できます。
少し別の話になりますが、Googleの提供するOfficeソフトは共有も容易かつ共同編集も可能なので数人~数百人程度の使用には非常におすすめです。


コメント