
2022年8月23日。世の画家の何割かが失業しかねないAIが無償公開されました。
Stable Diffusionというソフトウェアで、まだ開発途中と言いつつも適当な文言を与えるだけで高精度な画像を生成してくれる画家泣かせなツールとなっています。
これがローカル、つまり自分のPCで実行可能となったのです。
実行環境の準備
GPU
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512×512 images from a subset of the LAION-5B database. Similar to Google’s Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM. See this section below and the model card.
上記の通り最低限10GBはメモリを使用するので、最低限12GBくらいのGPUを用意する必要があるようです。
おいおい最適化や他製品にも対応していくとのことでしたが、現在公式にサポートしているのは「NVIDIA GeForce RTX 3080Ti」クラス以上のメモリを持ったNVIDIA製GPUということでしょう。
CUDA Toolkit
「CUDA Toolkit」を自分の環境に合わせてインストールします。
cuDNN
「cuDNN」をダウンロードします。
登録が必要ですが、簡単なのでちゃちゃっと終わらせましょう。
ZIP形式でダウンロードされるので、どこでもいいので解凍したフォルダを配置し、そのフォルダ内の「bin」フォルダを環境変数に追加します。
Anaconda
「Anaconda」というPythonの統合環境をインストールします。
元からPythonを使用している方には邪魔に感じるかもしれませんが、環境変数の優先順位を下げておけば弊害なく使用できるかと思います。
Git
ぶっちゃけ今のIT業界でGitが使えないのはアウトです。
Linux、Unix系ならさくっとインストールしておきましょう。
Windowsなら個人的には「Scoop」というパッケージマネージャがおすすめです。
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser -Force
iwr -useb get.scoop.sh | iexpowershell上で上記コマンドを実行し、
scoop install gitとすればGitが使用可能になります。
Stable Diffusion
セットアップ
git clone https://github.com/CompVis/stable-diffusion
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm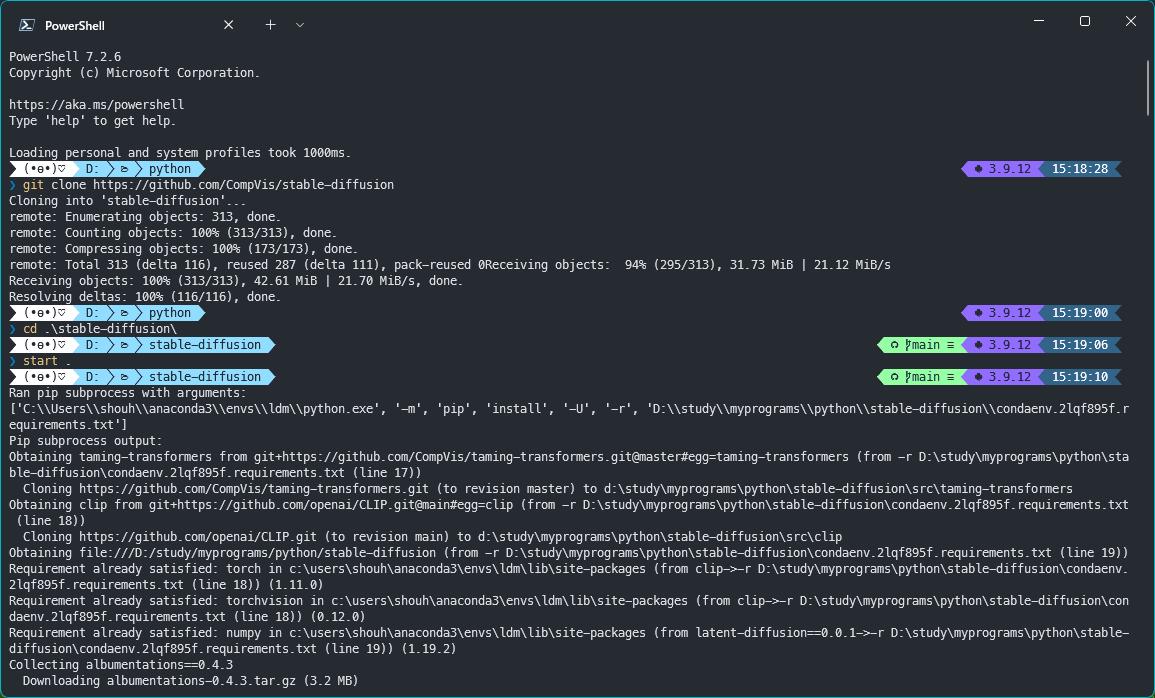
モデルのダウンロード
git clone https://huggingface.co/CompVis/stable-diffusion-v-1-4-original- 「
stable-diffusion-v-1-4-original」フォルダを「stable-diffusion-v1」にリネーム - 「
sd-v1-4.ckpt」を「model.ckpt」にリネーム - リネーム後、「
stable-diffusion-v1」フォルダを「stable-diffusion/models/ldm」フォルダに移動
実行例
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms 筆者の環境だと通常のPowershellではAnacondaがうまく動作しなかったので、「Anaconda Powershell Prompt」を使用しました。
実行結果ファイルは「outputs」以下に生成されます。
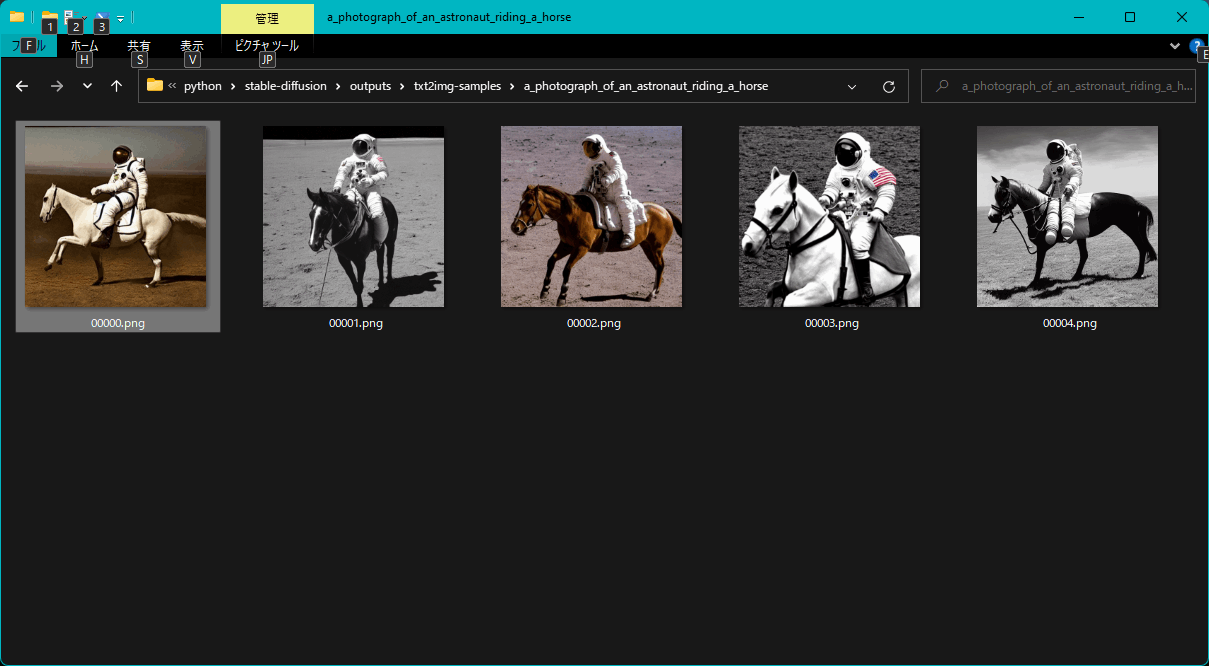
このように「a photograph of an astronaut riding a horse(馬に乗っている宇宙飛行士の写真)」が生成されました。
GPUメモリが10GBもない場合
実は筆者も NVIDIA GeForce RTX 3080 10GB なのでメモリが足りませんでした。
そこで代替案を2つ示します。
半精度モデルを使用する
公式に載っている方法です。
アクセストークンの取得
まずここにアクセスし、「Access repository」というボタンが表示されていればそこをクリックします。
アカウント作成画面が出てくるかと思うので、アカウントを作ります。
その後、画面右上にあるアイコンをクリックして「Settings → Access Tokens → New token」をクリックします。
「New token」がクリックできない場合はまだアカウントが認証されていない状態なので、「confirm emailなんちゃら」みたいなボタンを探してクリックして届いたメールのURLをクリックして認証してください。
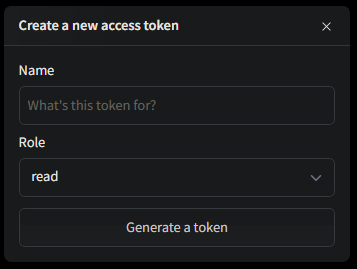
名前はテキトーで、RoleもそのままでOKで、「Generate a token」をクリックします。
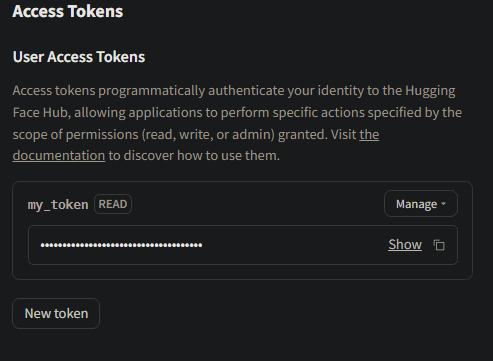
これでトークンが出来上がるので、どこかに控えておきましょう。
PyTorchのインストール
「CUDA Toolkit」と「cuDNN」はどの方法でも必要なので上記などを例にインストールしておきましょう。
続いて、「PyTorch」の公式サイトにアクセスし、自分の環境を選択して必要なコマンドを確認して入力します。
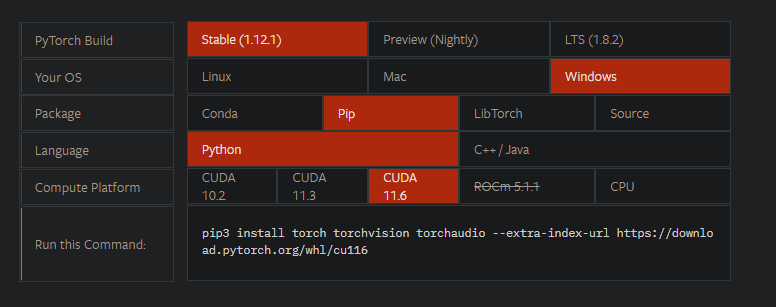
筆者はCUDA11.7なのですが、ここではCUDA11.6を選択しました。なぜか問題なく動きました。
その他必要パッケージのインストール
pip install diffusers==0.2.4 transformers scipy ftfyプログラム
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
TOKEN = "あなたのトークン"
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=TOKEN
)
pipe = pipe.to("cuda")
prompt = "a photograph of an astronaut riding a horse"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save(f"{prompt.replace(' ', '_')}.png")初回起動時にはモデルのダウンロードやリンク処理が行われます。
リンク処理に管理者権限が必要ですので初回だけ管理者権限で起動したプロンプトからプログラムを実行してください。
これで上記と同じ「馬に乗っている宇宙飛行士の写真」が生成されます。
たぶんおそらく精度は下がっていると思われますたぶん。
しかし、これでもGPUメモリを7GBくらいは使います。
さらにメモリが足りない場合は以下を試してみてください。
メモリ節約版
オリジナルではなく他者が作ったフォーク版(コピーして改造したもの)です。
git clone https://github.com/basujindal/stable-diffusion stable-diffusion-forkオリジナル版同様にクローンし、「stable-diffusion/models/ldm」フォルダに先程リネームした「stable-diffusion-v1」をコピーしてください。
オリジナル版の仮想環境が残っている場合は削除するかfork版の「environment.yaml」の「name: ldm」の部分を「name: ldm_fork」などに変更してください。
後はオリジナル版同様Anaconda Promptから
cd stable-diffusion-fork
conda env create -f environment.yaml
conda activate ldm_forkなどとして、実行は「optimizedSD」フォルダに有る「optimized_txt2img.py」を使用します。
python optimizedSD/optimized_txt2img.py --prompt "Cat_on_Dog"時間は上記よりはかかりますが、使用メモリは約4GBとかなり少なくすみます。

もっと簡単に試してみたい場合
公式デモサイトから試す
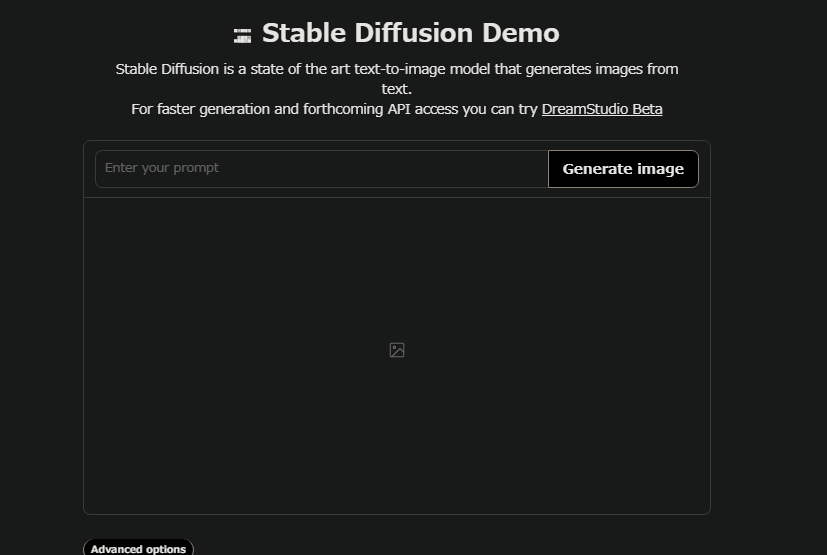
「こちら」のデモサイトから「Enter your prompt」に英語で生成したい画像の説明を入力し「Generate image」をクリックしてしばらく待つと画像が表示されます。
なぜか日本語で入力しても画像は生成されますが、おそらく英語の方が精度良く画像を生成してくれるような気がします。
Colaboratoryを使用する
Googleが提供するPython実行環境「Colaboratory」というサービスを使用しても画像の生成が可能なようです。
GIGAZINEさんが記事としてまとめてくださっていたのでこちらでの説明は省きます。
まとめ
まだ空想的な画像の生成は苦手のようですが、動画やホームページ、ブログなどの用途を考えるといらすとやさんレベルになるかもしれませんね。

コメント